
- Published on
BGP at Doors of Autonomous Systems is Simple
A comprehensive journey into modern data center networking technologies. Explore network virtualization, VXLAN tunneling, and BGP EVPN control planes through hands-on GNS3 implementation. Progress from Docker container setup through advanced overlay networking, gaining practical skills used by major cloud providers.
- Authors

- Name
- John Decorte
- Bluesky
42-BADASS: BGP at Doors of Autonomous Systems is Simple
The BADASS project represents a comprehensive journey into modern data center networking technologies, exploring the intricate world of network virtualization, VXLAN tunneling, and BGP EVPN control planes through hands-on implementation in GNS3. This ambitious undertaking bridges the gap between theoretical networking concepts and practical implementation, providing students with real-world skills that are highly sought after in the industry.
Overview
The BADASS (BGP At Doors of Autonomous Systems is Simple) project is structured as a multi-part networking challenge that progressively builds your understanding of contemporary data center networking technologies. Beginning with fundamental container networking concepts and advancing through to sophisticated BGP EVPN fabrics, this project mirrors the evolution of modern network architectures used by major cloud providers and enterprise data centers worldwide.
Throughout this journey, you will gain hands-on experience with technologies that power some of the world's largest network infrastructures. The project emphasizes not just theoretical knowledge, but practical implementation skills that are immediately applicable to production environments. By the conclusion of this project, you will have constructed a fully functional network virtualization lab that demonstrates the same principles used by companies like Amazon, Google, and Microsoft in their massive-scale data centers.
The project is carefully designed to introduce complexity gradually, ensuring that each new concept builds upon previously learned material. This pedagogical approach allows students to develop a deep, intuitive understanding of how modern networks operate at both the control plane and data plane levels.
Part 1 — GNS3 Configuration with Docker
The foundation of any networking project lies in having a reliable, flexible testing environment. This first part of the BADASS project introduces the setup of a comprehensive virtual lab environment using GNS3 and Docker, two powerful tools that have revolutionized network education and testing. GNS3 provides the graphical network simulation framework, while Docker offers lightweight, reproducible container images that can simulate various network devices without the overhead of full virtual machines.
The beauty of using Docker containers in network simulation lies in their efficiency and portability. Unlike traditional virtual machines, containers share the host operating system's kernel, resulting in minimal resource overhead while maintaining complete network isolation. This allows you to run complex multi-node topologies on modest hardware, something that would be impractical with full virtualization. Additionally, Docker images can be version-controlled and shared, ensuring consistent lab environments across different students and setups.
During this phase, you will create and configure two distinct Docker images, each serving a specific purpose in the overall network topology. The first image will function as a basic network host, capable of generating and receiving traffic for connectivity testing. The second image will serve as a fully-featured virtual router, equipped with multiple routing daemons that enable advanced routing protocols. This dual-image approach mirrors real-world network architectures, where edge hosts and routing infrastructure serve distinct but complementary roles.
Setting Up the Lab Environment
The initial step involves installing and configuring both GNS3 and Docker within your virtual machine environment. GNS3 serves as the graphical network topology designer and simulator, providing an intuitive interface for connecting virtual devices and monitoring network traffic. Docker, on the other hand, provides the containerization technology that makes running multiple isolated network nodes possible on a single physical machine. The integration between these two platforms allows you to drag Docker containers directly into your GNS3 topology, treating them as network devices that can be interconnected just like physical hardware.
Proper configuration of the lab environment is critical to project success. This includes ensuring that Docker networking is correctly configured to allow containers to communicate with the GNS3 virtual network infrastructure. You will need to configure Docker networking modes, enable IP forwarding on your host system, and potentially adjust firewall rules to permit inter-container communication. These configuration steps provide valuable experience with Linux networking fundamentals that underpin all modern network virtualization technologies.
Building the Host Container Image
The first Docker image you will create serves as a minimal network host, designed to be lightweight yet functional enough for comprehensive network testing. This image should be based on a small Linux distribution such as Alpine Linux or BusyBox, both of which provide complete functionality while maintaining an extremely small footprint. Alpine Linux, in particular, has become the de facto standard for containerized applications due to its security-focused design and minimal attack surface.
Here's an example Dockerfile for the host image:
FROM alpine:latest
# Install essential networking tools
RUN apk add --no-cache \
busybox-extras \
iproute2 \
iputils \
net-tools \
bind-tools \
tcpdump
# Keep container running
CMD ["/bin/sh"]
This host image must include essential networking utilities that enable you to test connectivity, troubleshoot issues, and verify network behavior:
- ping - ICMP connectivity testing to verify reachability between hosts
- ip - Advanced network interface configuration and routing table management
- ifconfig - Basic network interface status and configuration
- traceroute - Path discovery and latency measurement tools
- tcpdump - Packet capture for deep protocol analysis
These tools will be your primary diagnostic instruments throughout the project, allowing you to verify that each network configuration step has been implemented correctly.
Beyond basic connectivity testing, this host image will serve as the endpoint for traffic generation in later parts of the project. When you implement VXLAN tunnels and BGP EVPN in subsequent phases, these host containers will represent the actual workloads or end-user devices that the network infrastructure is designed to support. By keeping these hosts simple and focused, you can clearly distinguish between edge host behavior and core network infrastructure behavior, making troubleshooting significantly easier.
Building the Router Container Image
The second Docker image represents the heart of your virtual network infrastructure. This routing-capable image will function as a virtual router, running multiple routing protocol daemons that enable sophisticated network behaviors. Unlike the simple host image, this router image requires a more feature-complete Linux distribution and several specialized networking packages that implement various routing protocols.
The router image should include Zebra or Quagga, which serve as routing management daemons that integrate with the Linux kernel's routing table. These daemons provide a unified interface for multiple routing protocols, allowing them to share routing information and coordinate their activities.
Example Dockerfile for the router image:
FROM alpine:latest
# Install FRRouting (successor to Quagga)
RUN apk add --no-cache \
frr \
frr-pythontools \
iproute2 \
busybox-extras
# Enable IP forwarding
RUN echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf && \
echo "net.ipv6.conf.all.forwarding = 1" >> /etc/sysctl.conf
# Copy FRR daemon configuration
COPY daemons /etc/frr/daemons
# Expose BGP port
EXPOSE 179
CMD ["/usr/lib/frr/frrinit.sh", "start"]
The router image must include several routing protocol daemons:
- zebra - Core routing management daemon that interfaces with the kernel
- bgpd - Border Gateway Protocol daemon for inter-AS routing and EVPN
- ospfd - Open Shortest Path First link-state routing protocol
- isisd - Intermediate System to Intermediate System routing protocol
While this project focuses primarily on BGP for the EVPN control plane, having multiple routing protocols available provides flexibility for experimentation and allows you to compare different approaches to network routing. Each daemon runs as a separate process, communicating with zebra through a standardized API to inject and withdraw routes from the system routing table.
The configuration of these routing daemons follows traditional network equipment conventions, with each daemon typically having its own configuration file that specifies protocol-specific parameters. This configuration paradigm deliberately mirrors commercial routing equipment from vendors like Cisco and Juniper, providing you with transferable skills that apply directly to physical network hardware. Understanding how to configure and troubleshoot these routing daemons is essential not just for this project, but for anyone pursuing a career in network engineering or infrastructure operations.
Verifying Connectivity
Once both container images are built and imported into GNS3, the final step of Part 1 involves creating a simple topology and verifying that containers can communicate with each other. This verification process is crucial because it establishes the foundation upon which all subsequent work will build.
Basic connectivity test commands:
# On Host1 (10.1.1.2/24)
ip addr add 10.1.1.2/24 dev eth0
ip link set eth0 up
ip route add default via 10.1.1.1
# On Router (10.1.1.1/24 and 10.2.2.1/24)
ip addr add 10.1.1.1/24 dev eth0
ip addr add 10.2.2.1/24 dev eth1
ip link set eth0 up
ip link set eth1 up
# On Host2 (10.2.2.2/24)
ip addr add 10.2.2.2/24 dev eth0
ip link set eth0 up
ip route add default via 10.2.2.1
# Test connectivity from Host1 to Host2
ping 10.2.2.2
A simple verification topology might consist of two host containers connected through a single router container, forming a basic hub-and-spoke architecture. Each host should be assigned an IP address in a different subnet, with the router providing inter-subnet routing.
This verification phase also provides an opportunity to familiarize yourself with the GNS3 interface and container console access. You will need to open console sessions to each container, configure network interfaces, assign IP addresses, and potentially configure static routes. These basic network administration tasks might seem mundane, but they are fundamental skills that you will use repeatedly throughout the project. Taking the time to master these basics now will pay significant dividends as the project complexity increases in later parts.
Part 2 — Discovering VXLAN
With a functioning lab environment established, Part 2 introduces VXLAN technology, a crucial component of modern data center networking that enables Layer 2 network extension across Layer 3 infrastructure. Understanding VXLAN requires first understanding the limitations it was designed to overcome, which means examining the traditional VLAN technology that preceded it.
Understanding Traditional VLANs
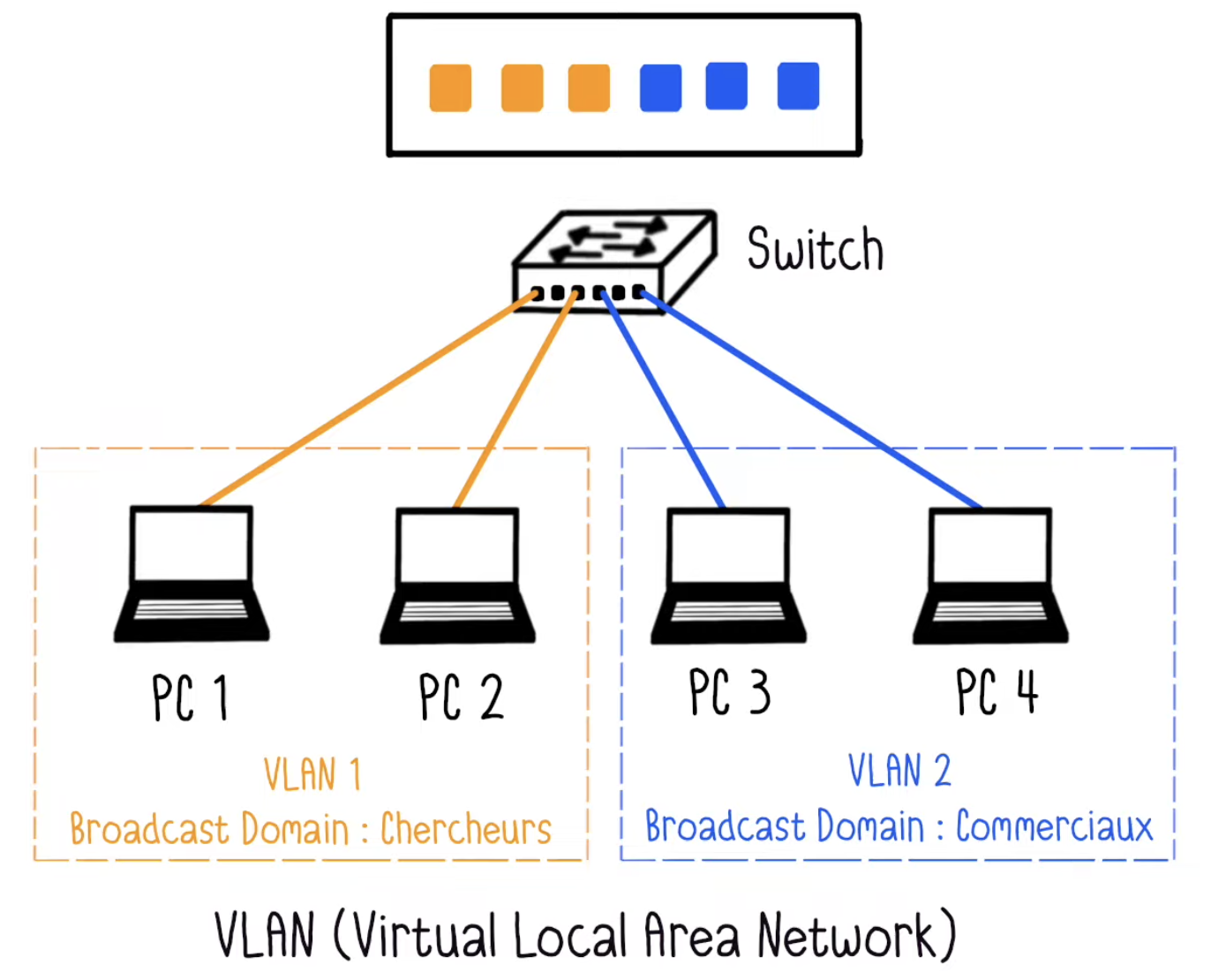
A VLAN, or Virtual Local Area Network, represents a logical subdivision of a physical network infrastructure. Unlike physical network segmentation, which requires separate switches and cabling for each isolated network, VLANs allow a single physical infrastructure to carry traffic for multiple logical networks. This virtualization of the network occurs at Layer 2 of the OSI model, the data link layer, where Ethernet frames are tagged with a 12-bit VLAN identifier.
The conceptual model of a VLAN is often described as creating virtual "rooms" within your network infrastructure. Devices within the same VLAN can communicate directly with each other at Layer 2, meaning their traffic never needs to traverse a router or be subjected to routing decisions. Conversely, devices in different VLANs cannot communicate directly, even if they are physically connected to the same switch. Any inter-VLAN communication must pass through a Layer 3 device like a router, which can apply security policies, access control lists, and other traffic management rules.
Traditional VLANs are encoded in Ethernet frames using the IEEE 802.1Q standard, which inserts a 4-byte tag into the Ethernet header containing the VLAN identifier. This 12-bit identifier field theoretically allows for 4096 unique VLANs, though in practice, some identifiers are reserved for special purposes, leaving approximately 4094 usable VLAN IDs. For traditional enterprise networks, this limit was generally sufficient, but the rise of cloud computing and multi-tenant data centers has exposed this limitation as a significant constraint.
The Limitations of Traditional VLANs
As data centers evolved to support cloud computing platforms, the limitations of traditional VLANs became increasingly apparent:
- Limited scale - Only 4096 available VLAN IDs (12-bit identifier)
- Geographic constraints - Cannot span multiple data centers without complex engineering
- Spanning Tree Protocol overhead - Forces network topology to block redundant links
- Manual provisioning - Requires configuration on every switch in the path
- Multi-tenancy challenges - Insufficient isolation for cloud-scale deployments
In a multi-tenant cloud environment, each customer or application might require network isolation from others, quickly exhausting the available VLAN ID space. Additionally, VLANs are fundamentally constrained to a single Layer 2 broadcast domain, meaning they cannot naturally span multiple geographically distributed data centers without complex and often fragile network engineering.
Another significant limitation of traditional VLANs relates to their reliance on Spanning Tree Protocol for loop prevention. STP works by blocking redundant links in the network topology, ensuring only a single active path exists between any two network segments. While this prevents broadcast storms and forwarding loops, it also means that significant portions of network bandwidth remain unused for normal traffic forwarding. In modern data centers where bandwidth utilization and efficiency are paramount, this waste is unacceptable.
The rigidity of VLAN provisioning also presents operational challenges in dynamic cloud environments. Adding a new VLAN typically requires configuration changes on every switch in the path, a manual and error-prone process that doesn't align well with the automated, API-driven infrastructure management paradigm of modern data centers. These limitations collectively drove the development of VXLAN as a more flexible, scalable alternative.
VXLAN Architecture and Design
VXLAN, or Virtual eXtensible LAN, addresses the limitations of traditional VLANs by taking a fundamentally different approach to network virtualization. Instead of tagging Ethernet frames with VLAN identifiers, VXLAN encapsulates entire Layer 2 Ethernet frames within Layer 3 UDP packets. This encapsulation strategy, sometimes called "MAC-in-UDP," allows Layer 2 network segments to be extended across any IP infrastructure, including routed networks that span multiple data centers or even geographic regions.
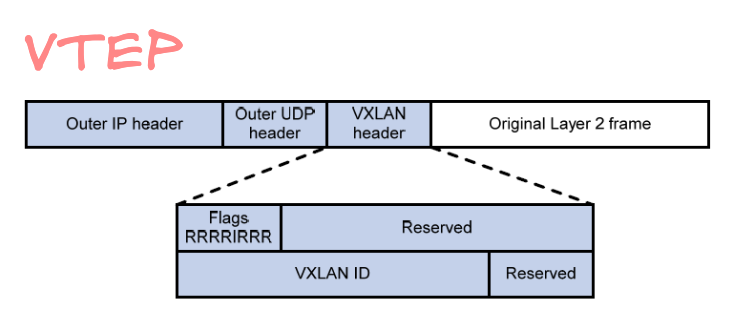
The VXLAN encapsulation format includes several important fields:
- VXLAN Header - 8 bytes containing flags and the VNI
- VNI (VXLAN Network Identifier) - 24-bit segment ID (16 million possible networks)
- Outer UDP Header - Uses destination port 4789 (IANA standardized)
- Outer IP Header - Routes the packet through the underlay network
- Outer Ethernet Header - Frames the packet for physical transmission
- Original Ethernet Frame - The complete Layer 2 frame being transported
With 24 bits available for the VNI, VXLAN supports up to 16 million unique network segments, a dramatic increase over the 4096 VLANs supported by 802.1Q. This massive address space is more than sufficient even for the largest multi-tenant cloud deployments.
Example VXLAN interface configuration:
# Create VXLAN interface on Linux
ip link add vxlan10 type vxlan \
id 10 \
dstport 4789 \
local 10.0.0.1 \
remote 10.0.0.2
# Bring up the interface
ip link set vxlan10 up
# Add to bridge
ip link add br0 type bridge
ip link set vxlan10 master br0
ip link set eth1 master br0
VXLAN packets are encapsulated within UDP datagrams using destination port 4789, which has been standardized by IANA for VXLAN traffic. The use of UDP rather than TCP provides several advantages, particularly avoiding the overhead of TCP connection establishment and state maintenance. Since the underlying IP network already provides routing and forwarding services, VXLAN doesn't need TCP's reliability features. In the rare case of packet loss, higher-layer protocols like TCP running within the encapsulated traffic will handle retransmission.
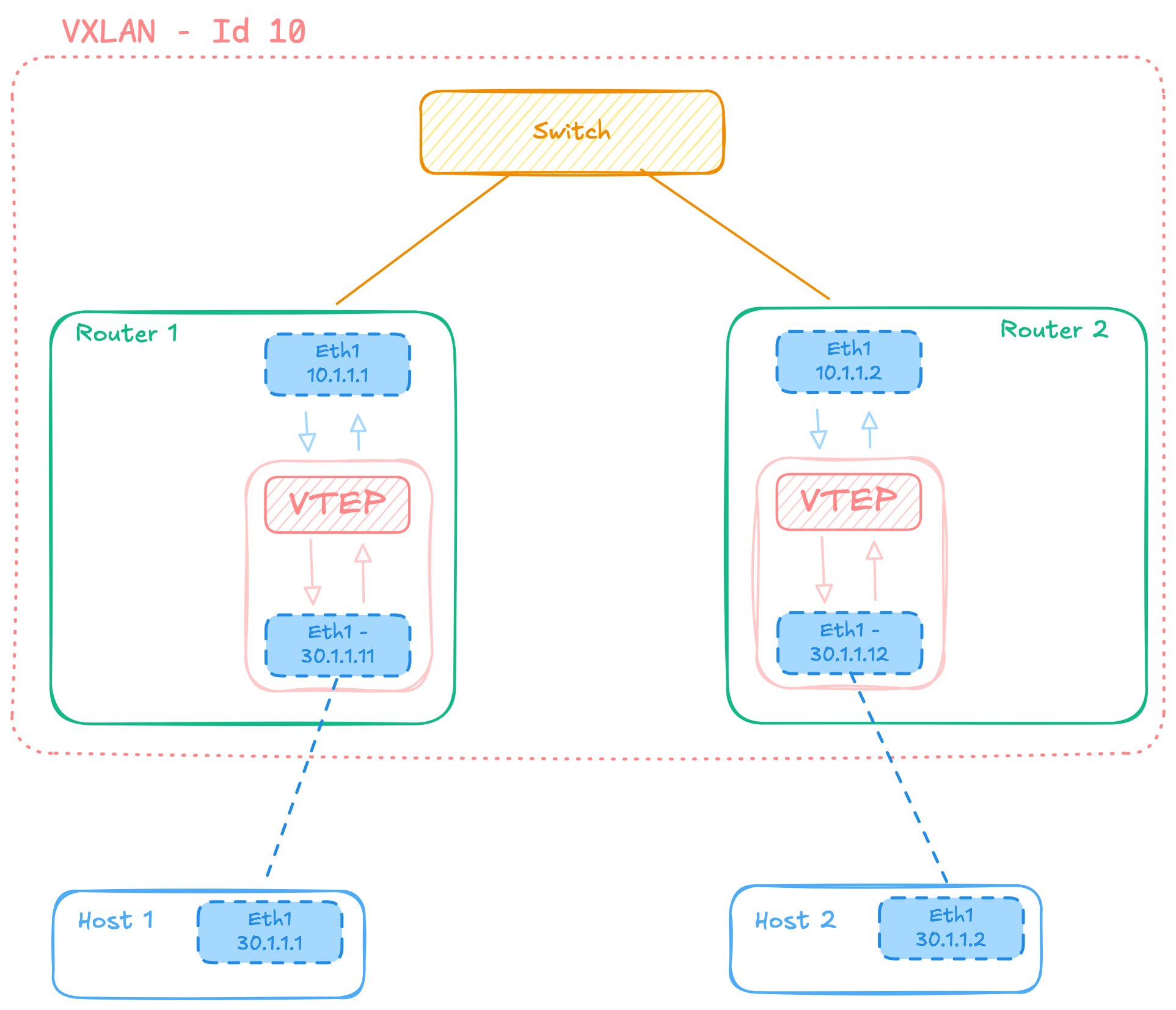
VTEP: The VXLAN Tunnel Endpoint
At the edge of each VXLAN segment sits a VXLAN Tunnel Endpoint, or VTEP, which performs the critical functions of encapsulation and decapsulation. A VTEP is typically implemented in either a physical network switch, a software virtual switch running on a hypervisor, or within the network stack of a container orchestration system. The VTEP serves as the gateway between the traditional Ethernet world and the VXLAN-encapsulated overlay network.
When a VTEP receives an Ethernet frame from a local host that needs to be sent to a destination on a remote network segment, it performs several operations. First, it determines which remote VTEP serves the destination MAC address, typically by consulting a lookup table populated through various learning mechanisms. Next, it constructs a VXLAN header containing the appropriate VNI for the network segment. Finally, it encapsulates the entire original Ethernet frame within a UDP packet addressed to the remote VTEP's IP address and transmits it into the underlay network.
The process operates in reverse when a VTEP receives a VXLAN-encapsulated packet. It extracts the original Ethernet frame from within the UDP payload, examines the destination MAC address, and forwards the frame out the appropriate local interface to reach the destination host. This decapsulation process is transparent to end hosts, which remain completely unaware that their traffic is being tunneled across an IP network. From the host perspective, they appear to be on a simple Layer 2 network with all other hosts in their VNI, regardless of the physical network topology.
The Performance Benefits of VXLAN
One of the significant advantages VXLAN brings to modern data centers relates to performance optimization through better broadcast domain management. Traditional Layer 2 networks can suffer from broadcast storms, where broadcast traffic consumes significant bandwidth and processing resources on every device in the network. VXLAN segments broadcast domains more effectively, limiting broadcast traffic to only those VTEPs that have members in a particular VNI. This scoping dramatically reduces unnecessary broadcast traffic replication across the data center infrastructure.
Additionally, VXLAN enables true multipath networking through Equal-Cost Multi-Path routing in the underlay network. Because VXLAN packets are standard IP packets, they can be load-balanced across multiple physical links using standard ECMP routing algorithms. The UDP source port in VXLAN packets is typically derived from a hash of the inner Ethernet frame's headers, ensuring that packets belonging to the same flow follow the same path through the network, preventing packet reordering while still allowing different flows to take advantage of multiple parallel paths.
The overlay nature of VXLAN also provides performance benefits through decoupling the overlay network topology from the underlay network topology. Network operators can optimize the underlay for maximum throughput and minimal latency without concern for the topology requirements of the overlay networks running on top. This separation of concerns simplifies network design and allows for independent scaling of underlay and overlay networks.
Security and Isolation with VXLAN
From a security perspective, VXLAN provides strong isolation between different tenant networks through the VNI segmentation mechanism. Traffic belonging to different VNIs is strictly isolated at the VTEP level, with no possibility of cross-contamination unless explicitly configured. This isolation is crucial in multi-tenant environments where different customers share the same physical infrastructure but require cryptographic-level separation of their network traffic.
By isolating users or applications into different VNIs, communication between them necessarily requires routing through a Layer 3 device where security policies can be enforced. This architecture enables granular security controls, including firewall rules, intrusion detection systems, and traffic inspection that can examine and filter traffic moving between network segments. The isolation also helps contain security incidents, preventing malware from one tenant or application from propagating to others sharing the same physical infrastructure.
This segmentation capability significantly enhances the overall security posture of the data center by reducing the attack surface available to potential threats. If a host in one VNI is compromised, the attacker gains no direct access to hosts in other VNIs, limiting the potential damage from any single breach. Security teams can implement different security policies for different VNIs, applying stricter controls to sensitive applications while allowing more relaxed policies for less critical workloads.
Cost Efficiency Through Network Virtualization
The economic benefits of VXLAN become apparent when considering the alternative of provisioning separate physical networks for each isolated application or tenant. Logical segmentation through VXLAN allows multiple virtual networks to share the same physical infrastructure, dramatically reducing both capital expenditure on network equipment and operational costs associated with managing multiple separate networks. This consolidation of infrastructure leads to better utilization of networking hardware and reduces the physical space, power, and cooling requirements in data centers.
The simplified management enabled by VXLAN also contributes to cost reduction. Rather than manually configuring VLANs on potentially hundreds of switches, network operators can define VXLAN segments programmatically through APIs or orchestration tools. This automation reduces the likelihood of configuration errors, speeds up provisioning times, and allows network engineers to focus on higher-value activities rather than repetitive configuration tasks. The operational efficiency gains from automation often provide greater long-term value than the initial capital cost savings.
Furthermore, VXLAN's flexibility in extending networks across data centers enables better resource utilization across multiple facilities. Workloads can be migrated between data centers without requiring network reconfiguration, allowing organizations to balance load, perform maintenance, or respond to failures more effectively. This flexibility translates directly into improved service availability and better return on infrastructure investments.
Part 3 — Discovering BGP with EVPN
The third and final part of the BADASS project introduces BGP EVPN, a sophisticated control plane protocol that automates and scales VXLAN deployments. While Part 2 demonstrated VXLAN's capabilities for network virtualization, manually configuring VXLAN tunnels between VTEPs quickly becomes impractical as the number of VTEPs grows. BGP EVPN solves this scaling challenge by providing a distributed, dynamic mechanism for VTEPs to discover each other and automatically establish VXLAN tunnels as needed.
Understanding BGP Fundamentals
Border Gateway Protocol has served as the routing protocol of the Internet for decades, responsible for exchanging routing information between the tens of thousands of autonomous systems that comprise the global Internet. BGP is a path vector protocol, meaning it maintains information about the complete path to each destination network, including all intermediate autonomous systems that traffic must traverse. This path information allows BGP to implement sophisticated routing policies based on business relationships, performance characteristics, or policy requirements.
What makes BGP particularly powerful is its extensibility through address family identifiers. Originally designed to carry only IPv4 routing information, BGP has been extended to support numerous other types of network layer reachability information through Multi-Protocol BGP extensions. These extensions allow BGP to carry routing information for IPv6, multicast topologies, VPN services, and, relevant to this project, EVPN routes that carry Layer 2 and Layer 3 reachability information for network virtualization overlays.
BGP operates by establishing TCP sessions between routers, over which routing updates are exchanged. The protocol is designed to be stable and efficient, sending only incremental updates when network reachability changes rather than periodically re-advertising all known routes. This efficiency becomes crucial in large-scale deployments where minimizing control plane overhead is essential for maintaining network stability. BGP's maturity, widespread deployment, and proven scalability make it an ideal foundation for building overlay network control planes.
EVPN: Extending BGP for Ethernet VPNs
EVPN, or Ethernet VPN, represents a significant evolution in BGP capabilities, extending it to carry Layer 2 MAC address reachability information alongside traditional Layer 3 IP routing information. This extension allows BGP to function as the control plane for VXLAN overlays, distributing information about which MAC addresses are reachable through which VTEPs. By leveraging BGP's existing scaling properties and distributed nature, EVPN provides a robust, proven mechanism for building large-scale overlay networks.
The key insight of EVPN is that MAC address learning, traditionally accomplished through flooding and the data plane, can instead be performed through explicit control plane signaling. When a VTEP learns a new MAC address from a locally connected host, it advertises that MAC address to all other VTEPs via BGP EVPN. Remote VTEPs receive this advertisement and install forwarding state, allowing them to send traffic directly to the correct VTEP without any flooding. This control plane learning dramatically reduces broadcast, unknown unicast, and multicast traffic in the network, improving efficiency and scalability.
EVPN also introduces the concept of route distinguishers and route targets, borrowed from BGP VPN technologies, to implement multi-tenancy and network segmentation. Each VNI is associated with a route target, and VTEPs import only the routes matching their configured route targets. This selective import mechanism ensures that each VTEP maintains forwarding state only for the VNIs it actually serves, reducing memory consumption and improving scaling. The route distinguisher ensures that identical MAC addresses in different VNIs are treated as distinct entities, preventing conflicts in the BGP routing table.
EVPN Route Types and Their Functions
EVPN defines several route types, each serving a specific purpose in the overall control plane architecture:
Type 2 Routes - MAC/IP Advertisement
Type 2 routes are the most fundamental EVPN route type. These routes carry MAC address and optionally IP address information for hosts connected to VTEPs. When a VTEP learns a new host MAC address, it generates a Type 2 route and advertises it via BGP to all other VTEPs participating in that VNI.
Key characteristics:
- Advertises host MAC addresses learned on local interfaces
- Optionally includes host IP address for ARP suppression
- Contains VNI information for multi-tenant segmentation
- Includes MAC mobility extended community for VM migration scenarios
Type 2 routes can include both MAC and IP address information, enabling VTEPs to perform ARP suppression. When a host sends an ARP request asking for the MAC address corresponding to an IP address, the local VTEP can consult its EVPN-learned information and respond directly to the ARP request without flooding it across the network.
Type 3 Routes - Inclusive Multicast Ethernet Tag
Type 3 routes handle the distribution of broadcast, unknown unicast, and multicast traffic, collectively known as BUM traffic. Each VTEP advertises a Type 3 route for each VNI it participates in, indicating its willingness to receive BUM traffic for that VNI.
Functionality:
- Signals VTEP participation in a VNI
- Establishes flood lists for BUM traffic distribution
- Enables ingress replication or multicast-based BUM handling
- Required for initial host discovery before Type 2 routes are learned
Type 5 Routes - IP Prefix Routes
Type 5 routes enable inter-VNI routing directly at the VTEP level. While Type 2 routes carry host-specific MAC and IP information, Type 5 routes carry IP prefix information, allowing VTEPs to act as gateways between different VNIs.
Capabilities:
- Advertises IP subnets rather than individual host addresses
- Enables Layer 3 routing between different VNIs
- Supports symmetric and asymmetric IRB (Integrated Routing and Bridging)
- Allows for centralized or distributed gateway architectures
Building the BGP EVPN Control Plane
Implementing BGP EVPN in your lab environment begins with configuring BGP sessions between all router containers acting as VTEPs. Unlike traditional BGP deployments where routers typically peer with only a few neighbors, EVPN fabrics often use route reflectors to reduce the number of required BGP sessions.
Example FRRouting BGP EVPN configuration for a VTEP:
# Configure BGP with EVPN on Router A (10.0.0.1)
router bgp 65000
bgp router-id 10.0.0.1
no bgp default ipv4-unicast
neighbor 10.0.0.254 remote-as 65000
neighbor 10.0.0.254 update-source lo
! Enable L2VPN EVPN address family
address-family l2vpn evpn
neighbor 10.0.0.254 activate
advertise-all-vni
exit-address-family
!
# Configure VXLAN interface with VNI 10
interface vxlan10
vxlan id 10
vxlan local-tunnelip 10.0.0.1
bridge-access 10
!
# Associate VNI with BGP EVPN
router bgp 65000
address-family l2vpn evpn
vni 10
rd 10.0.0.1:10
route-target import 65000:10
route-target export 65000:10
exit-vni
exit-address-family
!
The BGP configuration for EVPN requires enabling the EVPN address family in addition to the standard IPv4 unicast address family used for underlay routing. The underlay network provides basic IP reachability between VTEP loopback addresses, while the EVPN address family runs on top of this underlay.
Each VTEP must be configured with the VNIs it should participate in, along with the route distinguisher and route targets for each VNI. The route distinguisher ensures uniqueness of routes in the BGP table, while route targets control import and export of routes between different VNIs. Through careful configuration of these parameters, network operators can implement complex network policies, such as allowing some VNIs to communicate while keeping others isolated, or implementing hub-and-spoke topologies where multiple spoke VNIs can communicate only through a central hub VNI.
Dynamic VXLAN Tunnel Establishment
One of the most powerful features of BGP EVPN is its ability to dynamically establish VXLAN tunnels between VTEPs as needed. When a VTEP receives an EVPN route advertising a MAC address in a VNI it participates in, it automatically creates the necessary VXLAN tunnel state to forward traffic to the advertising VTEP. This dynamic tunnel creation eliminates the need for manual configuration of VTEP neighbors, dramatically simplifying operations and allowing the network to automatically adapt as VTEPs are added or removed.
The dynamic nature of tunnel establishment also enables more efficient resource utilization. Rather than maintaining full mesh tunneling between all VTEPs regardless of actual traffic patterns, tunnels are created only when needed to reach destinations with active hosts. In very large deployments, this on-demand tunnel creation significantly reduces the amount of state each VTEP must maintain, improving both memory efficiency and forwarding performance.
As hosts move between VTEPs, either through virtual machine migration or container rescheduling, BGP EVPN automatically updates the MAC address reachability information throughout the fabric. The VTEP where a host newly appears withdraws the old route and advertises a new route, causing all other VTEPs to update their forwarding tables. This mobility support is critical for modern data centers where workload migration is a routine operational procedure used for load balancing, maintenance, and failure recovery.
Validation and Troubleshooting
Validating your BGP EVPN implementation requires verifying several distinct layers of the solution:
Underlay Validation:
- Verify IP reachability between all VTEP loopback addresses
- Confirm underlay routing protocol convergence (OSPF/ISIS/static)
- Test ECMP functionality for load distribution
- Measure baseline latency and packet loss
Control Plane Validation:
- Verify BGP session establishment between VTEPs
- Confirm EVPN address family activation
- Check route target import/export configuration
- Validate Type 2, Type 3, and Type 5 route advertisements
Data Plane Validation:
- Test host-to-host connectivity across VTEPs
- Verify VXLAN encapsulation with packet capture
- Confirm MAC address learning via control plane
- Validate ARP suppression functionality
Essential troubleshooting commands:
# Check BGP neighbor status
show bgp summary
show bgp l2vpn evpn summary
# View EVPN routes
show bgp l2vpn evpn
show bgp l2vpn evpn route type 2
show bgp l2vpn evpn route type 3
# Check VNI status
show evpn vni
show evpn vni 10
show evpn vni 10 detail
# View MAC address table
show evpn mac vni 10
show evpn mac vni all
# Check VXLAN tunnel endpoints
show interface vxlan10
bridge fdb show
# Capture VXLAN traffic
tcpdump -i eth0 -n udp port 4789 -vv
# Verify underlay reachability
ping 10.0.0.2 -c 4
traceroute 10.0.0.2
At the underlay level, you must ensure that all VTEP loopback addresses are reachable via the IP routing table. Without proper underlay reachability, BGP sessions cannot be established, and the EVPN control plane will not function.
At the BGP control plane level, you should verify that BGP sessions are established between all VTEPs and route reflectors, and that EVPN routes are being exchanged correctly. The BGP daemon's show commands allow you to examine the BGP session state, view received and advertised EVPN routes, and verify that route targets are being processed correctly. Understanding how to interpret BGP command output is essential for troubleshooting EVPN issues, as control plane problems often manifest as missing or incorrect route advertisements.
Finally, at the data plane level, you must verify that traffic can actually flow between hosts in the same VNI across different VTEPs. This verification involves generating traffic between test hosts and using packet capture tools to examine both the overlay traffic seen by hosts and the encapsulated underlay traffic traversing the network. By examining VXLAN-encapsulated packets, you can verify that the correct VNI is being used, that traffic is being sent to the correct destination VTEP, and that encapsulation and decapsulation are functioning properly.
Topology Implementation
Implementing a functional EVPN fabric requires careful planning of the network topology. A minimal viable topology consists of at least two router containers acting as VTEPs, each with one or more host containers connected in the same VNI. This simple topology is sufficient to demonstrate the core EVPN functionality, including dynamic MAC address learning, VXLAN tunnel establishment, and inter-host communication across the fabric.
In this topology, Router A and Router B each run the BGP daemon with EVPN address family enabled. They establish a BGP session with each other, either directly or through a route reflector if you choose to implement one. Each router is configured with the same VNI, indicating that they are both members of the same virtual network segment. When hosts connected to each router begin communicating, the routers learn the host MAC addresses locally and advertise them via BGP Type 2 routes.
The VXLAN tunnel between the two routers is established automatically when they receive each other's EVPN route advertisements. From this point forward, traffic between Host 1 and Host 2 flows through the VXLAN tunnel, with Router A encapsulating frames from Host 1 and Router B decapsulating them before forwarding to Host 2. The reverse path operates identically, creating a bidirectional tunnel that is transparent to the hosts. The hosts themselves require no special configuration and are completely unaware that their traffic is being tunneled across an IP network.
Real-World Applications and Scaling Considerations
The technologies explored in the BADASS project are not merely academic exercises but represent the actual architectures used in production environments at massive scale. Major cloud providers use VXLAN with BGP EVPN control planes to provide network virtualization services to millions of customer workloads. The same principles you've implemented in your GNS3 lab scale to data centers with tens of thousands of physical servers and millions of virtual machines or containers.
In production deployments, additional considerations come into play, such as high availability, failure recovery, and performance optimization. Route reflectors are typically deployed in redundant pairs to eliminate single points of failure in the control plane. VTEPs are often dual-homed to multiple underlay switches to provide redundancy in the data plane. Traffic engineering techniques may be employed to optimize traffic flows across the underlay network, taking advantage of ECMP or traffic prioritization to ensure that critical workloads receive the necessary network resources.
As your understanding deepens, you might explore advanced features such as anycast gateway addresses, where multiple VTEPs respond to the same gateway IP address, enabling optimal routing and eliminating tromboning effects. You might also investigate integration with container orchestration platforms like Kubernetes, where VXLAN overlays provide pod networking that spans multiple physical hosts. The principles learned through this project provide a foundation for understanding and working with these more advanced concepts.
Key Takeaways
The BADASS project provides comprehensive, hands-on experience with technologies that define modern data center networking. Through this journey, you have gained:
Technical Skills:
- Container-based network simulation using GNS3 and Docker
- VXLAN overlay networking and encapsulation techniques
- BGP configuration and EVPN route type implementation
- Network troubleshooting across multiple protocol layers
- Linux networking and routing daemon configuration
Architectural Understanding:
- Modern data center fabric design principles
- Control plane vs. data plane separation
- Underlay and overlay network architecture
- Multi-tenancy and network segmentation strategies
- Scalability considerations for cloud-scale deployments
Operational Experience:
- Systematic validation and troubleshooting methodology
- Protocol debugging using standard tools
- Configuration management for complex systems
- Integration between multiple network technologies
- Performance analysis and optimization techniques
The progression from basic Docker networking through VXLAN overlays to BGP EVPN control planes mirrors the architectural evolution of real-world data centers over the past decade.
Understanding VXLAN fundamentals and Layer 2 overlay networking provides insight into how modern cloud platforms isolate tenant networks and provide virtual networking services at scale. The massive increase in available network segments from 4096 VLANs to 16 million VNIs enables the multi-tenant cloud computing paradigm that dominates today's IT landscape. Without VXLAN or similar overlay technologies, the cloud computing revolution would have been impossible at its current scale.
The BGP EVPN control plane represents the state of the art in overlay network automation. By leveraging BGP's proven scaling properties and distributed nature, EVPN provides a robust foundation for building networks that automatically adapt to changing conditions. The dynamic tunnel establishment and MAC address learning eliminate manual configuration overhead, enabling truly programmable network infrastructure that can be managed through APIs and orchestration tools.
Perhaps most importantly, this project develops troubleshooting and debugging skills that are essential for working with complex network systems. Learning to examine control plane state through BGP commands, verify data plane behavior through packet capture, and correlate problems across multiple network layers prepares you for the reality of production network operations. These skills, combined with the deep understanding of how modern network virtualization works, make you a more effective network engineer capable of designing, implementing, and operating sophisticated network infrastructure.
The hands-on nature of this project cannot be overstated in its importance. Reading about VXLAN and BGP EVPN provides theoretical knowledge, but actually configuring routers, troubleshooting connectivity issues, and seeing packets flow through the network cements that knowledge in a way that passive learning never can. The experience of building a working EVPN fabric from scratch, making mistakes, and ultimately succeeding provides both practical skills and the confidence necessary to tackle even more complex networking challenges in the future.